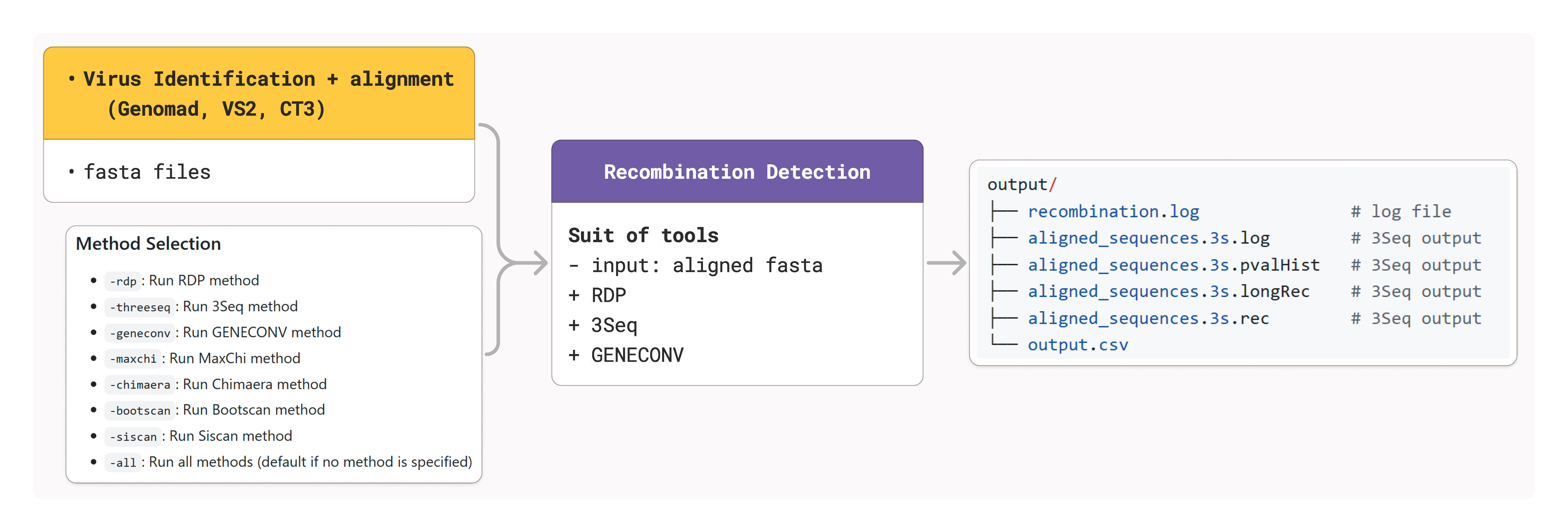
Recombination Detection Module
The recombination module detects recombination events in DNA sequences using multiple computational methods integrated through OpenRDP. It provides comprehensive recombination analysis using up to seven different detection algorithms.
Overview
Recombination is a crucial evolutionary process in viral genomes that can:
Generate genetic diversity
Create new viral strains
Influence host range evolution
Affect vaccine and therapeutic development
The recombination module implements multiple detection methods to ensure robust identification of recombination events.
Detection Methods
CRESSENT integrates seven recombination detection methods:
Primary Methods
RDP: Identifies recombination by detecting unusual phylogenetic relationships
GENECONV: Detects gene conversion events using statistical analysis
Bootscan: Uses bootstrap values to identify recombination breakpoints
MaxChi: Maximum chi-square method for breakpoint detection
Chimaera: Detects recombination using multiple reference sequences
3Seq: Three-sequence method for recombination detection
Siscan: Sister-scanning method for recombination identification
Method Reliability
Events detected by multiple methods (≥3) are considered highly reliable:
Algorithm Workflow
Sequence Preprocessing: Validates alignment quality and sequence integrity
Method Execution: Runs selected recombination detection algorithms
Statistical Analysis: Calculates p-values for detected events
Result Integration: Combines outputs from multiple methods
Significance Filtering: Applies statistical thresholds for reliable detection
Parameters
.ini configuration file defines the default OpenRDP parameters used by CRESSENT’s recombination detection module.
General Settings
circular_genome = False— ssDNA viruses often have circular genomes, but alignments are linearized before recombination scanning to avoid false breakpoints at the artificial sequence junctions. This flag disables circular wraparound scanning by default.comparison_correction = bonferroni— applies Bonferroni multiple-testing correction to maintain conservative significance thresholds across many pairwise tests, minimizing false positives in small viral datasets.
Permutation Options
num_permutations = 0— disables permutation-based empirical p-value estimation, favoring analytical p-values for faster runtime on large datasets. Users can increase this number for stricter validation when small sample sizes permit.
Data Processing
min_num_detecting_events = 1— requires that at least one independent method support a recombination event for it to be reported. Raising this threshold (e.g., 2 or 3) increases confidence but reduces sensitivity.
RDP Method
max_pvalue = 0.05— classical significance threshold.window_size = 30— scans triplets of sequences over 30-nt windows, appropriate for short ssDNA genomes (≈1–3 kb).min_identity / max_identity = 0–100— allows detection across full diversity range rather than limiting to closely related sequences.reference_sequence = None— indicates that all sequences are treated symmetrically (no fixed “reference” genome).
GENECONV Method
Detects unusually long identical fragments between sequences.
indels_as_polymorphisms = True— treats small indels as informative events rather than missing data.mismatch_penalty = 1,min_len = 1,min_poly = 2,min_score = 2— set liberal thresholds to detect short conversion tracts common in compact viral genomes.max_num = 1— limits redundant event reporting for the same region.
Bootscan Method
Performs sliding-window phylogenetic reconstruction.
win_size = 200,step_size = 20— windows of 200 bp shifted every 20 bp balance signal strength and resolution for 1–3 kb genomes.num_replicates = 100— bootstrap replicates per window.cutoff_percentage = 0.7— requires ≥70 % bootstrap support to accept a topology switch.model = Jukes–Cantor— simplest substitution model suitable for short alignments with limited divergence.p_value_calculation = binomial— uses binomial significance testing for breakpoint validation.
MaxChi and Chimaera Methods
Both use chi-square tests on substitution patterns.
win_size = 100–200andnum_var_sites = 60–70— define the number of polymorphic sites per window.strip_gaps = False— retains indel positions since compact viral genomes often contain informative indels.max_pvalue = 0.05— standard significance cutoff.
SiScan Method
Uses similarity profiles between sequences to detect topological shifts.
win_size = 200,step_size = 20— same window scheme as Bootscan for consistent resolution.pvalue_perm_num = 1100,scan_perm_num = 100— defines permutation counts for empirical p-value estimation and scanning.strip_gaps = True— removes gap-rich regions to avoid spurious similarity spikes.fourth_seq_sel = outlier— uses the most divergent sequence as the outgroup for normalization, which improves detection sensitivity across heterogeneous viral families.
Usage
Run All Methods
Detect recombination using all available methods:
cressent recombination \
-i sequences.fasta \
-o output/recombination \
-f recombination_results.csv \
--all
Run Specific Methods
Run selected methods for targeted analysis:
cressent recombination \
-i sequences.fasta \
-o output/recombination \
-f recombination_results.csv \
-rdp -bootscan -maxchi
Custom Configuration
Use custom parameters via configuration file:
cressent recombination \
-i sequences.fasta \
-o output/recombination \
-f recombination_results.csv \
-c custom_config.ini \
--all
Parameters
Required Parameters
-i, --input: Input alignment file in FASTA format-o, --output: Output directory for results-f, --output_file: Output CSV file name for results
Method Selection
-rdp: Run RDP method-threeseq: Run 3Seq method-geneconv: Run GENECONV method-maxchi: Run MaxChi method-chimaera: Run Chimaera method-bootscan: Run Bootscan method-siscan: Run Siscan method-all: Run all available methods
Optional Parameters
-c, --config: Configuration file for method parameters-quiet: Suppress console output-verbose: Enable detailed logging
Output Format
The recombination analysis produces a comprehensive CSV file with the following structure:
Column |
Description |
|---|---|
Method |
Detection method used |
Recombinant |
Sequence identified as recombinant |
Major_Parent |
Predicted major parent sequence |
Minor_Parent |
Predicted minor parent sequence |
Breakpoint_Start |
Start position of recombination region |
Breakpoint_End |
End position of recombination region |
Pvalue |
Statistical significance of detection |
Multiple_Comparisons |
Corrected p-value |
Example Output
Method |
Recombinant |
Major_Parent |
Minor_Parent |
Breakpoint_Start |
Breakpoint_End |
Pvalue |
Multiple_Comparisons |
|---|---|---|---|---|---|---|---|
RDP |
Sequence_A |
Sequence_B |
Sequence_C |
245 |
678 |
0.0023 |
0.0156 |
Bootscan |
Sequence_A |
Sequence_B |
Sequence_C |
240 |
685 |
0.0034 |
0.0204 |
MaxChi |
Sequence_A |
Sequence_B |
Sequence_C |
250 |
670 |
0.0019 |
0.0133 |
Result Interpretation
Statistical Significance
P-value < 0.05: Statistically significant recombination event
P-value < 0.01: Highly significant recombination event
Multiple methods: Events detected by ≥3 methods are most reliable
Breakpoint Analysis
Examine breakpoint positions to understand:
Recombination hotspots: Regions with frequent breakpoints
Functional domains: Impact on protein function
Phylogenetic implications: Effect on evolutionary relationships
Data Analysis Workflow
Python Analysis Example
import pandas as pd
import matplotlib.pyplot as plt
# Load recombination results
df = pd.read_csv("recombination_results.csv")
# Filter significant events
significant = df[df['Pvalue'] < 0.05]
# Count methods per recombinant
method_counts = significant.groupby('Recombinant')['Method'].value_counts().unstack(fill_value=0)
method_counts['Total_Methods'] = method_counts.sum(axis=1)
# Identify reliable events (≥3 methods)
reliable_events = method_counts[method_counts['Total_Methods'] >= 3]
print("Reliable recombination events:")
print(reliable_events)
# Plot breakpoint distribution
plt.figure(figsize=(10, 6))
plt.hist(significant['Breakpoint_Start'], bins=20, alpha=0.7)
plt.xlabel('Breakpoint Position')
plt.ylabel('Frequency')
plt.title('Distribution of Recombination Breakpoints')
plt.show()
Integration with Phylogenetic Analysis
Recombination detection should be performed before phylogenetic analysis:
# 1. Detect recombination
cressent recombination \
-i sequences.fasta \
-o recombination/ \
-f recomb_results.csv \
--all
# 2. Align sequences
cressent align \
--input_fasta recombination/cleaned_sequences.fasta \
-o alignment/
# 3. Analyze results and potentially remove recombinant sequences
# 4. Build phylogenetic trees with cleaned dataset
cressent build_tree \
-i alignment/cleaned_alignment.fasta \
-o phylogeny/
Best Practices
Input Preparation
High-quality alignment: Ensure proper sequence alignment before analysis
Sufficient diversity: Include adequate sequence diversity for detection
Appropriate length: Sequences should be long enough to detect meaningful events
Method Selection
All methods: Use all methods for comprehensive analysis
Cross-validation: Require detection by multiple methods for reliability
Statistical thresholds: Apply appropriate p-value cutoffs
Result Validation
Manual inspection: Examine alignments around detected breakpoints
Phylogenetic analysis: Compare trees before/after recombinant removal
Functional analysis: Consider impact on protein function
Common Applications
Outbreak Investigation
Trace recombination events in epidemic strains
Identify parent strains in recombinant viruses
Understand transmission dynamics
Vaccine Development
Identify stable genomic regions for vaccine targets
Assess recombination risk in vaccine strains
Monitor vaccine escape variants
Troubleshooting
Common Issues
No Events Detected Check alignment quality and sequence diversity. Ensure adequate evolutionary distance.
Binary Compilation Errors The module automatically compiles required binaries. Check system compatibility and dependencies.
Memory Issues Reduce dataset size or increase available memory. Some methods are computationally intensive.
Statistical Significance Adjust p-value thresholds based on study requirements and multiple testing considerations.
Performance Considerations
Dataset size: Larger datasets require more computational time
Sequence length: Longer sequences provide more power but increase runtime
Method selection: Running all methods increases accuracy but computational cost
Parallel processing: Some methods can utilize multiple CPU cores
Example Complete Analysis
#!/bin/bash
# Complete recombination analysis workflow
echo "Starting recombination analysis..."
# 1. Prepare alignment
cressent align \
--threads 24 \
--input_fasta viral_genomes.fasta \
-o analysis/alignment
# 2. Run comprehensive recombination detection
cressent recombination \
-i analysis/alignment/viral_genomes_aligned_trimmed_sequences.fasta \
-o analysis/recombination \
-f comprehensive_recombination.csv \
--all \
--verbose
# 3. Generate summary report
echo "Analysis complete. Results in analysis/recombination/"
echo "Check comprehensive_recombination.csv for detailed results"